Many marketing and advertising experts are certainly permanently looking for the most cost-effective solutions for their on-line advertising campaigns to be more competitive on the market. Agencies and media operators are responsible for their clients’ marketing campaigns. They have to rely on measurement to optimize many campaigns’ metrics such as ROI, CR or profit. However, manually going through multiple campaign statistics can be very ineffective. Moreover, it is not possible to ensure by the human operators that the campaigns remain profitable on all domains, as this requires combining knowledge of many different statistics. The biggest challenge is that there are thousands of domains where our ads are shown. We have to block domains before we collect statistically significant information about CR per domain, because gathering thousands of clicks is very costly.
In this post, Adam Dobrakowski our Data Mining Expert presents how useful it can be to look through and analyze data collected in e-commerce. Our algorithm increased the profit by 50% by only blocking a part of non-profitable traffic.
The challenge
Our client carries out marketing campaigns by displaying advertisements and would like to maximize the conversion rate (CR). Each campaign is managed on advertising networks (like MGID, Exoclick, etc.) by a human operator. The ad networks provide control panels, where operators can perform various actions, like blocking specific websites (domains), modifying stake per click or replacing ads to increase the profitability of the campaign.
The biggest challenge is that there are thousands of domains where our ads are shown, and we have to block domains before we collect statistically significant information about CR per domain, because gathering thousands of clicks is very costly.
Solution
We define traffic-fingerprints for UIDs (unique traffic source ID) which are defined as normalized 24-dimensional vectors representing the number of clicks collected in each hour of the day over the history of interaction with each page. Then we divide the traffic-fingerprints into groups using k-means clustering. Finally, we treat pages in each cluster jointly, i.e., we turn all of them on or off during specific hours. This approach allowed us to increase the profit of our MGID-campaigns by 53%.
Algorithm
(1) Clustering of domains
We select only domains with at least 50 clicks (to obtain on average at least 2 clicks per hour in traffic-fingerprints). Then we apply k-means clustering. We consider the number of clusters between 2 and 15 for each ad network, and determine the optimal number of clusters according to the Elbow method (https://en.wikipedia.org/wiki/Elbow_method_(clustering). Finally, we measure the clusters’ quality using a silhouette score.
(2) Creating blocking rules
Figure 1.
(3) Reassigning domains to clusters
Having computed clusters of domains on historical data, we fix clusters’ centers. Then, while we are collecting new traffic on domains, we update traffic-fingerprints for domains. Finally, for each domain we select the closest cluster.
Offline experiments
For offline experiments, we have split data into train and test sets for each ad network. We have computed clusters and created blocking rules on the train set. Then, we simulated clusters’ blocking and compared it with real results on the test set.
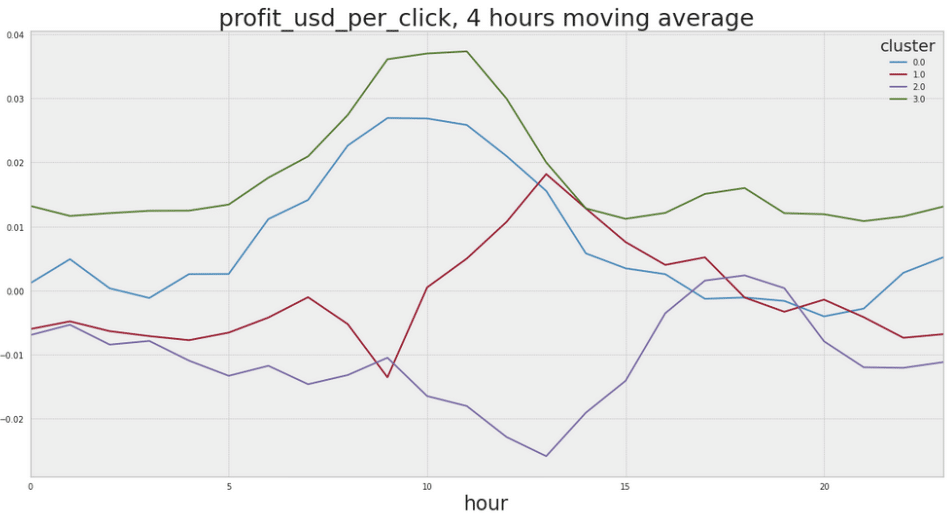
Below we can see click-fingerprints for identified clusters’ centers for four ad networks. There is a clear difference in daily traffic patterns between the clusters. For most examples, there are 2 clusters. Only for MGID we detected 4 clusters.
Figure II.
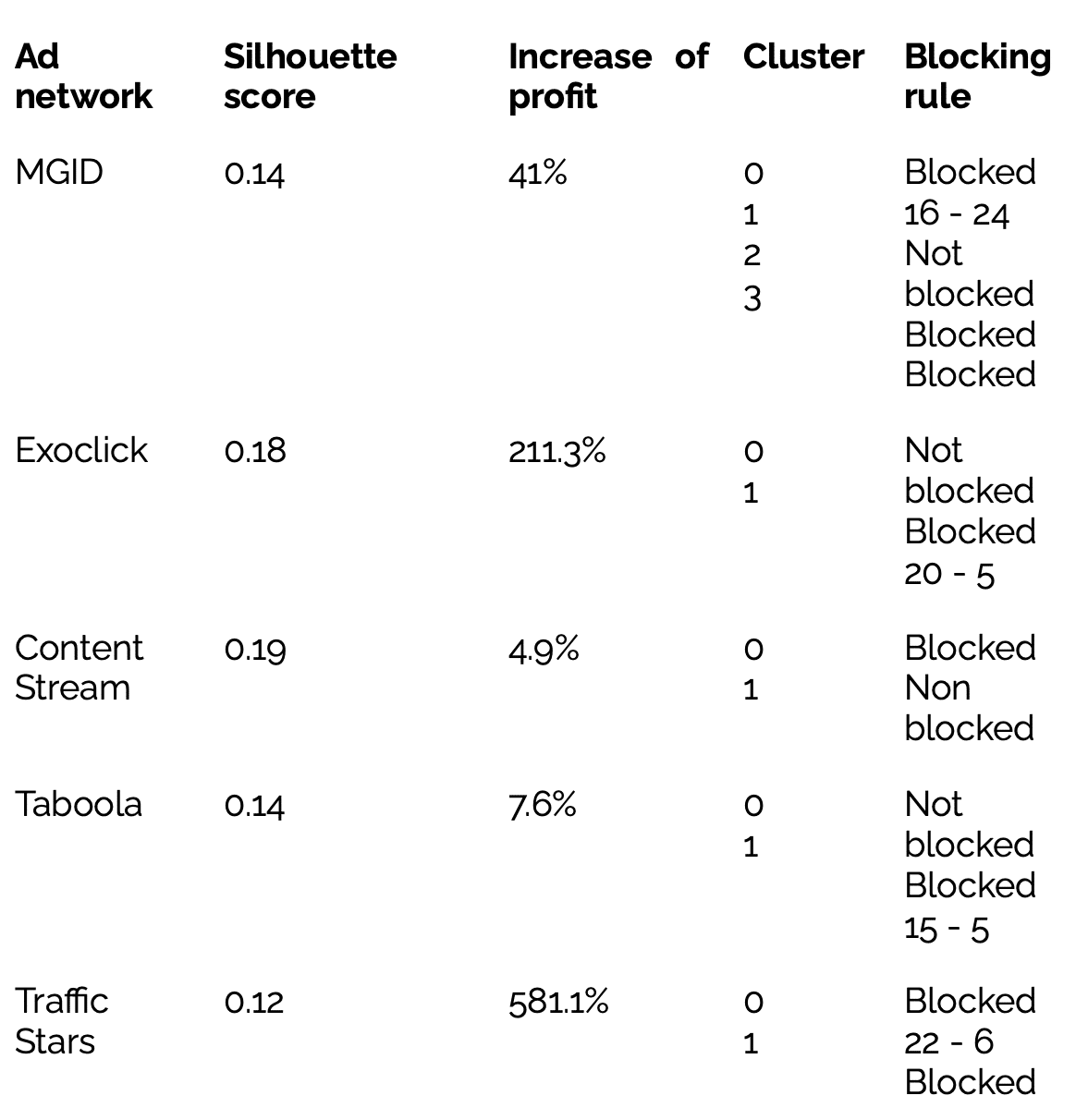
In the offline experiment, our algorithm for each ad network was profitable. We could observe very large values of percentage profit because in some cases the real profit was close to 0.
Table 1.
A very interesting observation is that less profitable clusters have lower CR not only during evening and night hours but also for other hours of the day. We can see this phenomenon
for Taboola clustering, but for other ad networks we could observe similar patterns.
This indicates that the identified clusters are not just some coincidence, but represent domains with different types of daily activities that can be identified by their traffic.
Figure III.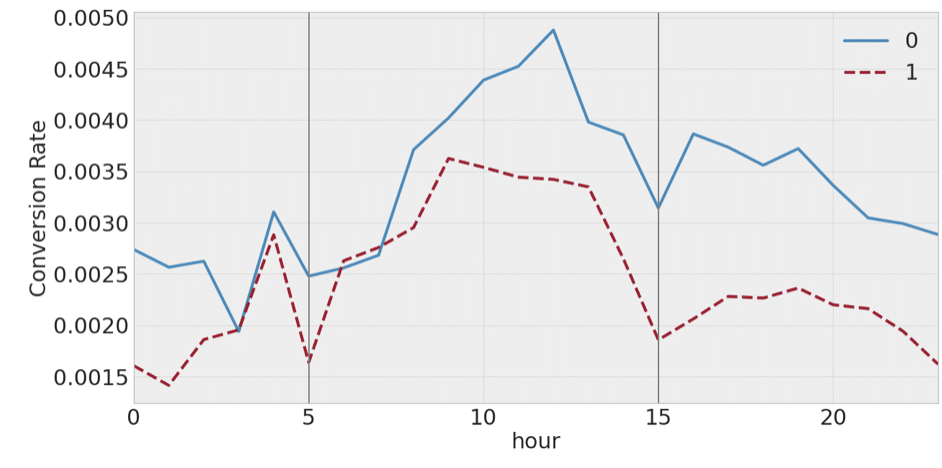
Online experiments
We executed online experiments with our algorithm on several campaigns on the MGID platform. The campaigns were optimized semi-automatically: the algorithm was responsible for blocking domains and human operators selected bids, modified ads, etc.
We selected a subset of all active campaigns and ran the algorithm on this subset, while human operators managed the other part of the campaigns as before. This way, we could compare the periods before and after running optimization, and also the results for two campaign groups.
We have been monitoring all campaigns’ performance on MGID from the beginning of June 2021. Then, on the 7th of July we randomly selected about half of the campaigns and began the optimization by the algorithm. Finally, on the 9th of September we turned on the algorithm for all active campaigns.
Below we can see 14-days moving averages of the total profit per click for optimized and non-optimized campaigns. Vertical lines indicate the days when the algorithm was turned on for some campaign groups. Despite the high variability of the metric, we can observe a noticeable jump in the performance after turning on the optimization in both time stamps.
Figure IV.
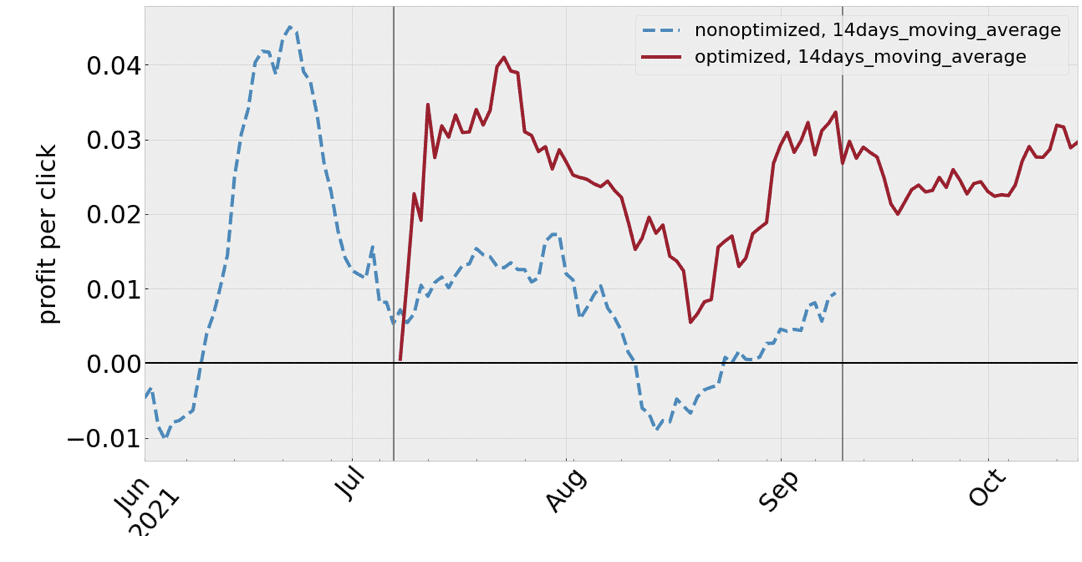
Table II.
We created an algorithm that can effectively manage blocking less effective domains in ad networks. The algorithm detects bigger groups of domains that have similar properties and can be managed jointly. This way, we do not have to spend a lot of money validating every domain separately. There is an automated solution, which is our algorithm that increased a profit by over 40% both in offline simulations on historical data and as well as online on real e-commerce campaigns.
The whole case study and solution is descibed in the scientific paper: “Improving Ads-Profitability Using Traffic-Fingerprints” written by: Adam Gabriel Dobrakowski, Andrzej Pacuk, Piotr Sankowski, Marcin Mucha, and Pawel Brach. Read more>>


